前言
大家用过ChatGPT的GPTs的同学,应该都知道它的厉害,它能上传你自己的模型,实现最接受你风格的AI,简单讲,就是可以利用已有数据,生成特定的自定义模型。可以上传自己的视频,文本,图片,等内容,今天就介绍一下最简单的入门爬虫,收集自己喜欢的数据,训练自己的AI模型。
项目
官方项目地址:https://github.com/builderio/gpt-crawler
官方有使用说明,这里再结合我自己的过程,记录一下。
有三种运行项目的方式,前提是你要安装好node.js>=16版本以上。
方式一:CMD
这个是最简单的,配置环境最少的
第一步,直接下载zip代码到本地,并解压
第二步,在资源管理器地址栏输入CMD,或者开始菜单进入的项目目录,确保已在项目目录下
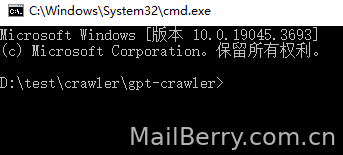
第三步,输入以下命令安装项目
npm i
第四步,配置爬虫目录,编辑config.js文件 import { Config } from "./src/config";
export const defaultConfig: Config = {
url: "https://www.builder.io/c/docs/developers",
match: "https://www.builder.io/c/docs/**",
maxPagesToCrawl: 50,
outputFileName: "output.json",
};
url:替换成你的目录地址
match:目录下所有文件
maxPagestoCrawl:50,这个是数量
outputFileName:输出结果的文件名
第五步,运行项目
npm start
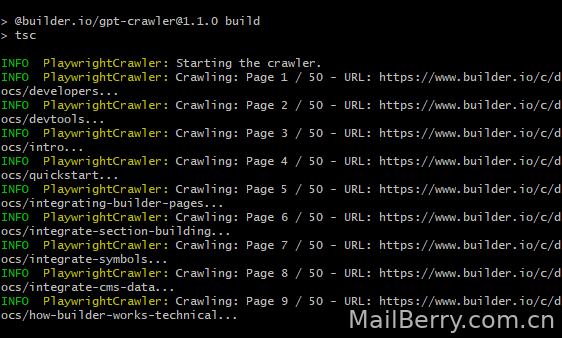
这样跑起来,就是在爬虫了,到最后会得到了个
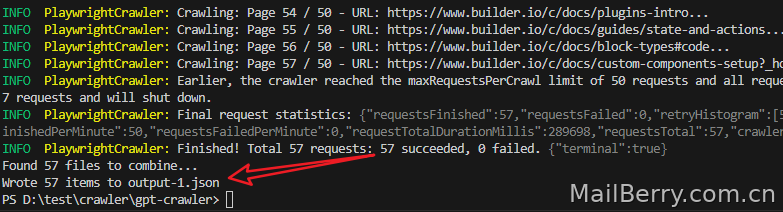
至此,已经爬虫数据保存在output-1.json文件里面了
方式二:GIT
先在任意目录右键,Git Bash Here
会打开一Bash终端
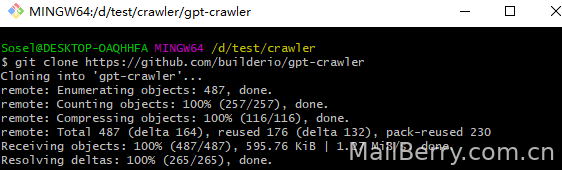
然后:git clone https://github.com/builderio/gpt-crawler
克隆项目,后面步骤跟上面的第三步一样了
方式三:VScode
直接右键,通过Code打开
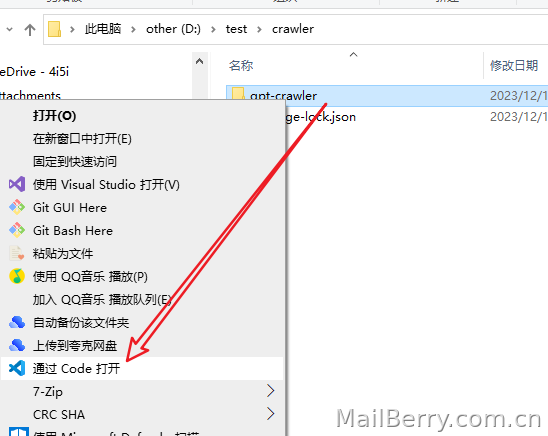
然后 编辑config.js
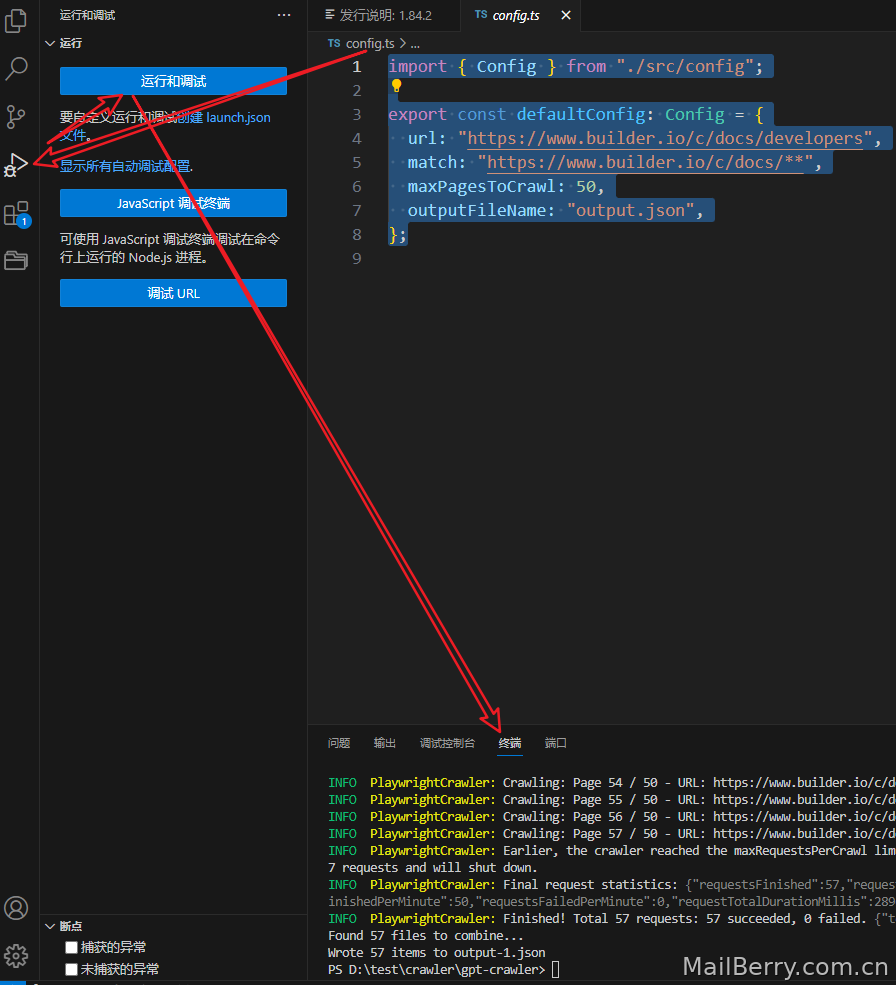
调试使用终端,后面步骤也跟第三步一样安装,开始就行了
导入
GPTs导入很简单,直接新建新的GPTs,上传文件
第一步,先Explore
第二步,Create a GPT
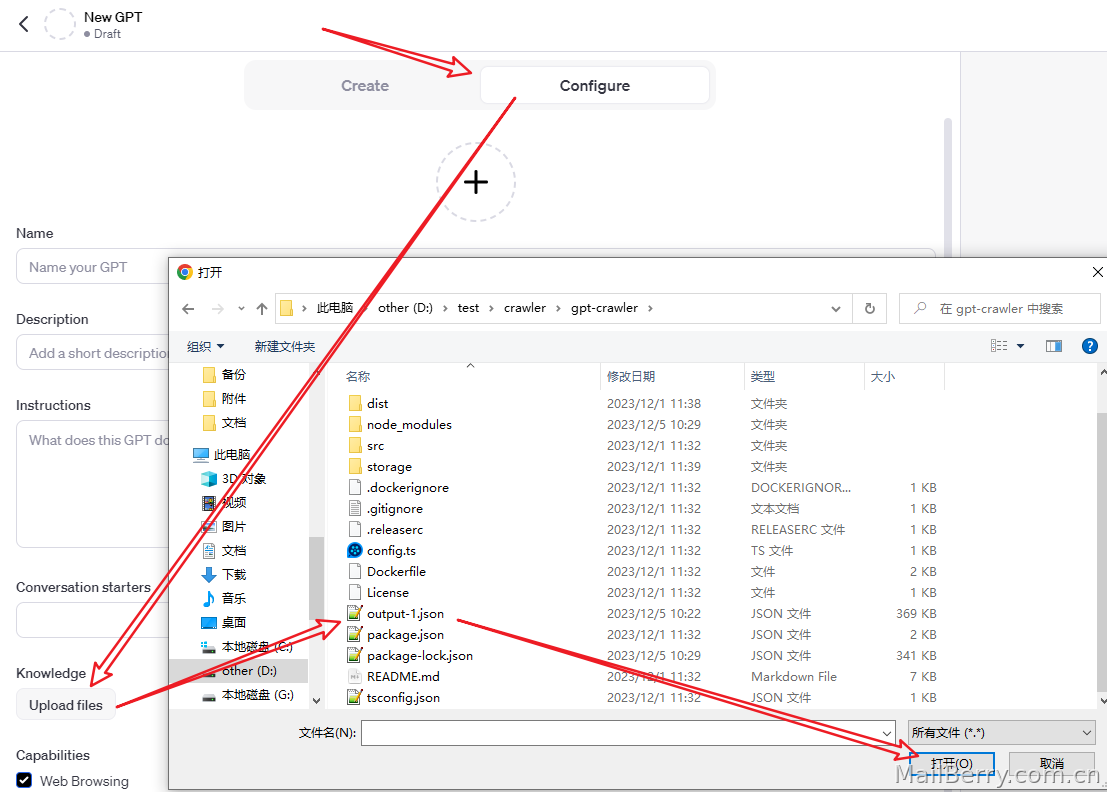
第三步,上传json文件,完结
结果

这是我爬虫后,创建的Json文件,让GPTs总结的,说明数据都已经被GPT消化了,接下来就是你自己的使用了,祝君使用愉快
总结
过程非常的简单,只要替换自己的目标URL就可以了,爬虫有风险,请自行评估,这里只是作为技术方向分享。








暂无评论